Git
优点
- 相对于svn优势在于他是分布式的,这就意味着你的每一个developer都有一个 完整的历史拷贝在本地仓库。不需要像svn一样担心一旦中央仓库出现问题,就彻底game over。
- 因为有一个本地仓库,所以在没有联网的情况下也能进行工作。
- 分支的优势
- 基于内容寻址的存储系统,
记录的是内容,而不是文件
分支模型
- 常驻分支
- development-从master创建
- poroduction-也就是master,默认分支
- 活动分支
- feature 从development分支创建
- hotfix 从master创建,用于测试
- release 从development分支创建,标识一个产品的正式发布
- 常驻分支
git status
- 三个区域
- 工作目录
- 暂存区
- 提交区
- 文件状态
- 未跟踪
- 已跟踪
- git status 命令就是用来帮助我们来了解这些区域的状态。并帮助我们了解这些文件的变化。
- 三个区域
- git add 就是把指定的文件添加到暂存区,并且该文件从未跟踪变成了已跟踪 (
可以通过git add .来添加整个目录的文件) - 忽略文件
- 在添加时忽略
仅仅作用于未追踪的文件!相当于在未跟踪与跟踪之间加了一层过滤。
- git rm
- 如果只是想从暂存区删除,使用git rm –cached 即可
- 如果希望从暂存区和工作目录一起删除 使用git rm就行
- 希望删除所有被跟踪但是在工作目录被删除的文件,使用 git rm $(git ls-files –delete)
其中git ls-files列出了所有在暂存区的文件
- git commit
- 根据暂存区内容完成一次提交
- git log 查看提交历史,更简单的一种方式是git log –oneline
- git config可以用来设置别名:git config alias.shortname
- git diff 直接输入的话是显示工作目录与暂存区的差异。如果git diff –cached 则是显示暂存区与某次提交之间的差异,默认为HEAD,HEAD指向当前的提交
- git checkout “file” 将文件内容从暂存区复制到工作区。
相当于撤销对工作区的修改- git check 在本质上实际就是用来移动HEAD这个指针,而HEAD是指向当前的提交。所以他同时也会把当前的工作目录和暂存区移到你指定的版本。也就是会把那个版本的内容复制到工作目录和暂存区。
- git reset HEAD “file” 将文件内容从上次提交复制到暂存区。
相当于撤销了对暂存区的操作 - git checkout HEAD “file” 直接将提交区文件复制到工作目录。
相当于撤销全部改动
- git branch “branchname” 创建一个分支.git branch -d “branchname” 删除一个分支. git branch -v 查看现在所有的分支
- git cheackout
- git checkout “branchname” 切换到某个分支
- git checkout -b “branchname” 直接创建一个分支,并切换到他
- git checkout 《reference》 也可以将他切换到任何的引用对象上
- git checkout - 回到上一个分支
- 当你不用分指名作为参数而把提交版本号作为参数传入git checkout时,这时称为detached head。此时应尽量避免提交东西。以为没有引用会指向这个提交记录。只有HEAD而已。当你HEAD重新回到master时,你刚刚所做的提交都会被视为没有被引用。最后会被git的垃圾回收机制回收。
所以当处于分离操作时一般不要做写操作,而是读取他的内容 - git reset 将当前分支回退到历史某个版本
- git reset –mixed “commit” (默认)此时他会将当前内容复制到暂存区
- git reset –hard “commit” 同时会将内容复制到工作目录
- git reset –soft “commit” 暂存区和工作目录不会有任何变化,此时万一是从最新的提交上转移到别的地方,那么那个最新的提交就会丢失了。并且git log已经找不到了。此时可以使用git reflog来解决。他排出了你HEAD切换分支的路径,那么你就可以通过版本号再次定位到那个最新的分支
- 使用捷径
- A^表示A上的父提交
- A~n 表示A之前的第n次提交
- git stash save “somemessage”这种情况一般发生在如下情景,就是你在一个分支进行着工作,一直使用着工作区,还没有将改变的内容添加进暂存区,此时突然另一个分支有一个紧急任务需要完成,但是你又没法切换过去因为一旦这样工作区就会被污染,这个命令就给了我们解决办法。她保存了目前的工作目录和暂存区的状态,并返回到干净的工作空间。其实除了之前所说的工作区,暂存区,提交区以外,还有一个就是stash区。
- git stash list 查看当前stash里有多少保存的内容
- git stash apply stash@{0}可以让保存的内容重新恢复到我们的工作目录
- git stash drop stash@{0} 将记录从stash区域删除
- stash pop= stash apply+stash drop
- git merge 合并分支 当你在master分支上时直接后面加上你要合并的分支名就好。
- 当出现冲突后使用git add,然后git commit一下来完成这次冲突的解决
- 当你在某个节点创建了分支,然后master分支一直没有移动,而是一直在next分支进行操作,然后进行merge时则不会出现想象的那种两种分支合并的效果,而是会把master分支直接指向next分支。还有一种情况就是没有出冲突,也会这样。如此之后我们的提交历史就会变得线性。但是这样会使得我们看提交历史变得不清晰,如果希望不要变得线性,可以使用git merge “branchname” –no-ff命令
- git tag 为某次提交设置一个不变的别名,如某次发布后版本为v0.3那么可以设置这次提交为git tag v0.3 e39d0b2 很显然,第二个参数就是某次提交的哈希。以后直接使用这个标签名就能访问那个版本。
- git是支持本地协议的,所以我们是可以初始化一个本地的远程服务器的使用git init ~/git-server –bare
- git push 用于提交到中央仓库,他实际上做的是一个复制的操作,他会把本地的提交历史完整的拷贝一份到远程仓库。
- git remote 对远程仓库进行操作。
- git remote add origin ~/git-server 添加一个别名。 一般会把远程的分支别名取名为origin。而且本地是会和远程仓库一样会有一个origin分支的。
- 使用git fetch来获取远程仓库的提交历史。一般出现在当你要同步到远程仓库的时,远程仓库在相同的父节点下已经有一个提交,此时会要你先同步远程代码到本地。 一旦同步,你本地的origin分支就会变化,此时你在git merge origin 一下,然后提交。
- git pull= git fetch + git merge
- git clone 克隆一个远程仓库作为本地仓库 他就等于git init+git remote+git pull
Database
- 我们在使用数据库连接的时候就一行代码conn= DriverManager.getConnection()然而他的背后是非常复杂的
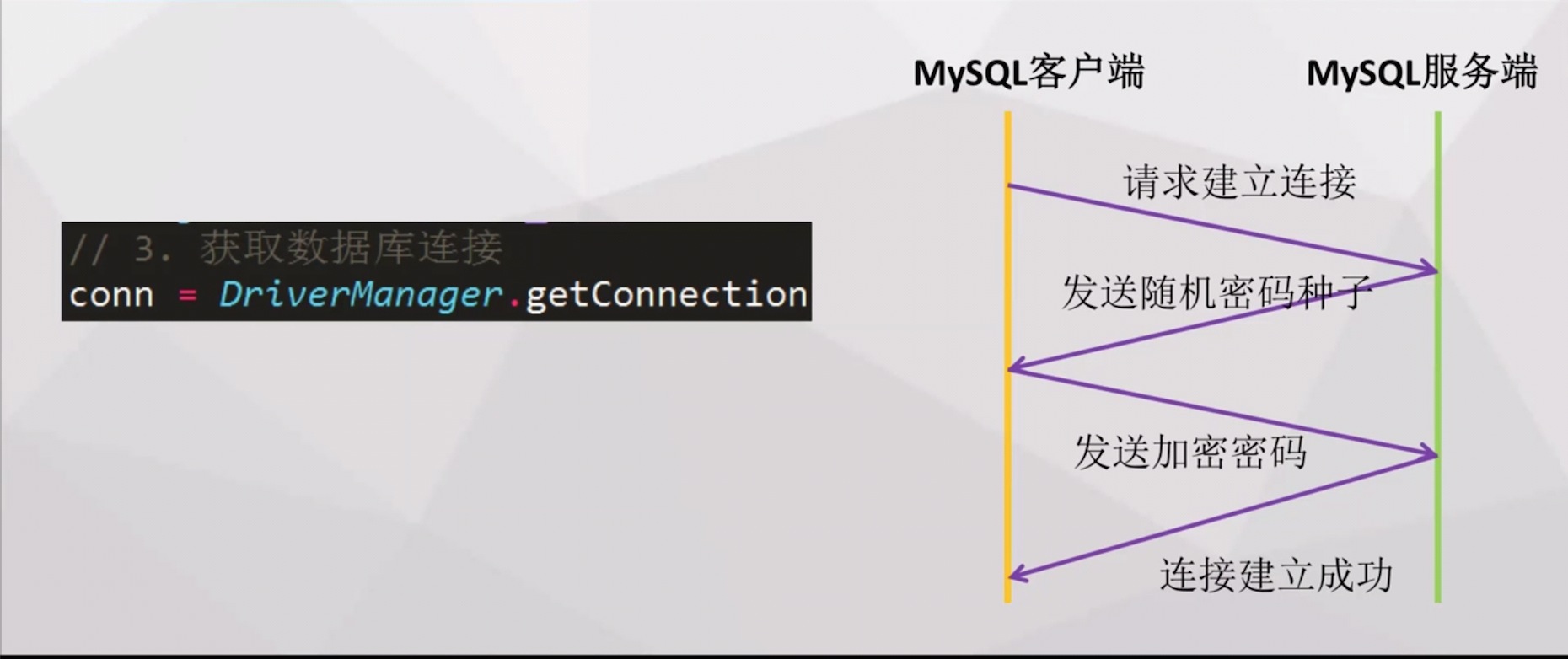 因此建立连接的开销很大
因此建立连接的开销很大 - 连接池的优势在于使原来创建连接变成了租借连接,并且数据库每次建立一个连接就会创建一个线程,每创建一个线程就会在内存占用一些空间,所以服务器端是要限制最大连接数的,一旦超过了这个连接数就会报异常,重则宕机。这样的反馈方式实在不够友好,我们应该在建立连接的地方就做好限流,起到对后端数据库保护的作用。
- 后端数据库连接过多时就会存在更多锁的冲突与检测,加大服务器资源的资源消耗。
- 连接池就是一组jar包。目前使用最广泛的是dbcp,他包括三个jar包,分别是commons-dbcp,commons-pool,commons-logging。可以使用maven进行管理。具体怎么写依赖参考 Maven Repository
- 数据库连接池的底层还是使用jdbcÇ
使用dbcp最重要的是BasicDataSource这个对象。获取到这个对象后需要对他设置url,username,password,drivername用于访问数据库。然后访问步骤就和使用jdbc差不多了。具体代码如下:
12345678910111213141516171819202122232425262728293031323334353637public static BasicDataSource ds=null;//连接池初始化public static void InitDBPool(){ds=new BasicDataSource();ds.setUrl(DB_URL);ds.setDriverClassName(DRIVER_NAME);ds.setUsername(USER_NAME);ds.setPassword(PASSWORD);}//连接并查询public static void DBPoolTest(){Connection conn=NULL;Statement stmt=NULL;ResultSet rs=NULL;try{conn=new Connection();stmt=conn.createStatement();rs=stmt.executeQuery("select * from users");if(rs.next){System.out.println(rs.getString("username")) ;}}catch(SQLException e){e.printStackTrace();}finally{try{if(conn!=null) conn.close();if(stmt!=null) stmt.close();if(rs!=null) rs.close();}catch(Exception e2){e2.printStackTrace();}}}public static void main(String[] args){InitDBPool();DBPoolTest();}前面说过我们是可以设置连接池的一些属性的。这里有几个重要的参数
- .setInitialSize() 这个表示一开始启动连接池时就要有多少连接数
- .setMaxTotal() 最多能有多少连接数
- .setMaxWaitMills() 一旦连接满载,等待队列的最大等待时间
- .setMaxldle() 连接池能有的最大空闲连接数
- .setTestWhileldle(True) 数据库的物理连接一般8小时后自动关闭,如果超过这个时间一些在连接池的连接没有被销毁,那么这就是一个失效的连接,无法使用。为了保证我们所有的连接都是可以用的,我们需要对每个连接的连接空闲时间进行检查,这就是打开这个动作的开关。
- .setMinEvictableldle() 设置连接空闲时间的最小值,一旦某个连接的空闲时间大于这个值,则销毁他。一般都是要小于数据库连接的自动销毁时间,也就是8小时。
- .setTimeBetweenEvitionRunsMills() 检查连接空闲时间的间隔。
- 事务与锁
- mysql是以行加锁的方式来避免不同事务对同一行进行修改的。
- mysql数据库分为两大类锁,一种是排它锁,一种是共享锁。排它锁一旦一个事务获取,则其他事务想要获取时必须等待,而共享锁是可以不用等待,直接获取的。
- 加锁方式
- 外部加锁,由应用程序添加,通过sql语句添加
- 内部加锁 由系统内部自动添加,与sql执行,事务隔离级别息息相关
- mysql所有的select语句都是快照读,支持不加锁。这保证了mysql的性能。他可以保证同一个select结果集是一致的。但是不能保证同一个事务内部,select语句和其他语句的数据一致性,如果业务需要,那么需要通过外部显示加锁的方式。如:select lock in share mode 或 select for update的方式
- 更新,插入,删除,还有外部显示加锁的读都是需要持有锁的
- show engine innodb status 命令可以列出发生死锁时所有等待的sql语句,也会列出系统强制回滚的是哪些事务
- ORM 帮助我们建立对象到数据库关系的映射,对程序员来说就使得他们可以像操作对象一样操作数据库。具体的就是通过这个技术,可以将关系型数据库的二元表的每行转换成一个对象,每一列转换成一个属性。
- mybatis 本质就是一个ORM的框架。但与传统的ORM框架显著不同的是它不是建立对象到表的映射关系,而是建立对对象的操作到sql语句的关系。他使用xml或者注解配置
- 每个mybatis都是基于一个叫SqlSessionQFactory实例为中心的,通过这个实例可以获取将对象操作转换成数据库sql的session。
- 当数据库对象和对象之间是多对多的关系时可能需要一张关系表来记录,如果是一对多的关系直接在多的那张表上加上一个字段用来标识另一个就行。
- mybatis 最重要的就是两个xml配置文件,全局的conf用来配置数据库连接这些,另一个在包内部的xml文件用来写sql语句,并且匹配查询的结果。
- 我认为mybatis最大的优势就是让sql语句不再嵌在java代码中,使得代码更好管理。其次就是返回的结果非常友好,因为mybatis自动装在进了你定义的javabean,这样就更能以面向对象的方式读返回的结果了。